

- Add short-term memory as a part of your agent’s state to enable multi-turn conversations.
- Add long-term memory to store user-specific or application-level data across sessions.
Add short-term memory
Short-term memory (thread-level persistence) enables agents to track multi-turn conversations. To add short-term memory:Use in production
In production, use a checkpointer backed by a database:Example: using Postgres checkpointer
Example: using Postgres checkpointer
You need to call
checkpointer.setup() the first time you’re using Postgres checkpointer- Sync
- Async
Example: using [MongoDB](https://pypi.org/project/langgraph-checkpoint-mongodb/) checkpointer
Example: using [MongoDB](https://pypi.org/project/langgraph-checkpoint-mongodb/) checkpointer
Setup
To use the MongoDB checkpointer, you will need a MongoDB cluster. Follow this guide to create a cluster if you don’t already have one.
- Sync
- Async
Example: using [Redis](https://pypi.org/project/langgraph-checkpoint-redis/) checkpointer
Example: using [Redis](https://pypi.org/project/langgraph-checkpoint-redis/) checkpointer
You need to call
checkpointer.setup() the first time you’re using Redis checkpointer- Sync
- Async
Use in subgraphs
If your graph contains subgraphs, you only need to provide the checkpointer when compiling the parent graph. LangGraph will automatically propagate the checkpointer to the child subgraphs.Read short-term memory in tools
LangGraph allows agents to access their short-term memory (state) inside the tools.Write short-term memory from tools
To modify the agent’s short-term memory (state) during execution, you can return state updates directly from the tools. This is useful for persisting intermediate results or making information accessible to subsequent tools or prompts.Add long-term memory
Use long-term memory to store user-specific or application-specific data across conversations.Use in production
In production, use a store backed by a database:Example: using Postgres store
Example: using Postgres store
You need to call
store.setup() the first time you’re using Postgres store- Sync
- Async
Example: using [Redis](https://pypi.org/project/langgraph-checkpoint-redis/) store
Example: using [Redis](https://pypi.org/project/langgraph-checkpoint-redis/) store
You need to call
store.setup() the first time you’re using Redis store- Sync
- Async
Read long-term memory in tools
A tool the agent can use to look up user information
- The
InMemoryStoreis a store that stores data in memory. In a production setting, you would typically use a database or other persistent storage. Please review the store documentation for more options. If you’re deploying with LangGraph Platform, the platform will provide a production-ready store for you. - For this example, we write some sample data to the store using the
putmethod. Please see the BaseStore.put API reference for more details. - The first argument is the namespace. This is used to group related data together. In this case, we are using the
usersnamespace to group user data. - A key within the namespace. This example uses a user ID for the key.
- The data that we want to store for the given user.
- The
get_storefunction is used to access the store. You can call it from anywhere in your code, including tools and prompts. This function returns the store that was passed to the agent when it was created. - The
getmethod is used to retrieve data from the store. The first argument is the namespace, and the second argument is the key. This will return aStoreValueobject, which contains the value and metadata about the value. - The
storeis passed to the agent. This enables the agent to access the store when running tools. You can also use theget_storefunction to access the store from anywhere in your code.
Write long-term memory from tools
Example of a tool that updates user information
- The
InMemoryStoreis a store that stores data in memory. In a production setting, you would typically use a database or other persistent storage. Please review the store documentation for more options. If you’re deploying with LangGraph Platform, the platform will provide a production-ready store for you. - The
UserInfoclass is aTypedDictthat defines the structure of the user information. The LLM will use this to format the response according to the schema. - The
save_user_infofunction is a tool that allows an agent to update user information. This could be useful for a chat application where the user wants to update their profile information. - The
get_storefunction is used to access the store. You can call it from anywhere in your code, including tools and prompts. This function returns the store that was passed to the agent when it was created. - The
putmethod is used to store data in the store. The first argument is the namespace, and the second argument is the key. This will store the user information in the store. - The
user_idis passed in the config. This is used to identify the user whose information is being updated.
Use semantic search
Enable semantic search in your graph’s memory store to let graph agents search for items in the store by semantic similarity.Long-term memory with semantic search
Long-term memory with semantic search
Manage short-term memory
With short-term memory enabled, long conversations can exceed the LLM’s context window. Common solutions are:- Trim messages: Remove first or last N messages (before calling LLM)
- Delete messages from LangGraph state permanently
- Summarize messages: Summarize earlier messages in the history and replace them with a summary
- Manage checkpoints to store and retrieve message history
- Custom strategies (e.g., message filtering, etc.)
Trim messages
Most LLMs have a maximum supported context window (denominated in tokens). One way to decide when to truncate messages is to count the tokens in the message history and truncate whenever it approaches that limit. If you’re using LangChain, you can use the trim messages utility and specify the number of tokens to keep from the list, as well as thestrategy (e.g., keep the last maxTokens) to use for handling the boundary.
- In an agent
- In a workflow
To trim message history in an agent, use
pre_model_hook with the trim_messages function:Full example: trim messages
Full example: trim messages
Delete messages
You can delete messages from the graph state to manage the message history. This is useful when you want to remove specific messages or clear the entire message history. To delete messages from the graph state, you can use theRemoveMessage. For RemoveMessage to work, you need to use a state key with add_messages reducer, like MessagesState.
To remove specific messages:
When deleting messages, make sure that the resulting message history is valid. Check the limitations of the LLM provider you’re using. For example:
- some providers expect message history to start with a
usermessage - most providers require
assistantmessages with tool calls to be followed by correspondingtoolresult messages.
Full example: delete messages
Full example: delete messages
Summarize messages
The problem with trimming or removing messages, as shown above, is that you may lose information from culling of the message queue. Because of this, some applications benefit from a more sophisticated approach of summarizing the message history using a chat model.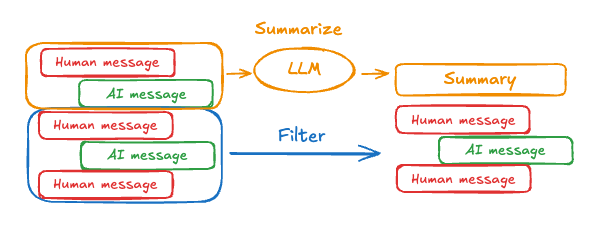
- In an agent
- In a workflow
To summarize message history in an agent, use
pre_model_hook with a prebuilt SummarizationNode abstraction:- The
InMemorySaveris a checkpointer that stores the agent’s state in memory. In a production setting, you would typically use a database or other persistent storage. Please review the checkpointer documentation for more options. If you’re deploying with LangGraph Platform, the platform will provide a production-ready checkpointer for you. - The
contextkey is added to the agent’s state. The key contains book-keeping information for the summarization node. It is used to keep track of the last summary information and ensure that the agent doesn’t summarize on every LLM call, which can be inefficient. - The
checkpointeris passed to the agent. This enables the agent to persist its state across invocations. - The
pre_model_hookis set to theSummarizationNode. This node will summarize the message history before sending it to the LLM. The summarization node will automatically handle the summarization process and update the agent’s state with the new summary. You can replace this with a custom implementation if you prefer. Please see the create_react_agent API reference for more details. - The
state_schemais set to theStateclass, which is the custom state that contains an extracontextkey.
Full example: summarize messages
Full example: summarize messages
- We will keep track of our running summary in the
contextfield
SummarizationNode).- Define private state that will be used only for filtering
call_model node.- We’re passing a private input state here to isolate the messages returned by the summarization node
Manage checkpoints
You can view and delete the information stored by the checkpointer.View thread state
- Graph/Functional API
- Checkpointer API
View the history of the thread
- Graph/Functional API
- Checkpointer API